Research
Publications
Teaching/TAing
Pictures
Other work
Food Delivery
Photo Map
Worked at Faro Technologies on the Laser Tracker from December 2015 to February 2019 (See videos here and here for more info about Faro Laser Tracker).
Worked at Canfield Scientific on software for medical devices such as the Vectra WB360 and IntelliStudio from October 2019 to October 2024 (See brochures here and here for more info about the devices).

Contact
- Email: sgrauerg@gmail.com
- Resume: Resume
- GitHub: https://github.com/sgrauerg6
- Google Scholar: https://scholar.google.com/citations?user=y35b43QAAAAJ
- LinkedIn: https://www.linkedin.com/in/scott-grauer-gray-30992a1a
Bicycle food delivery
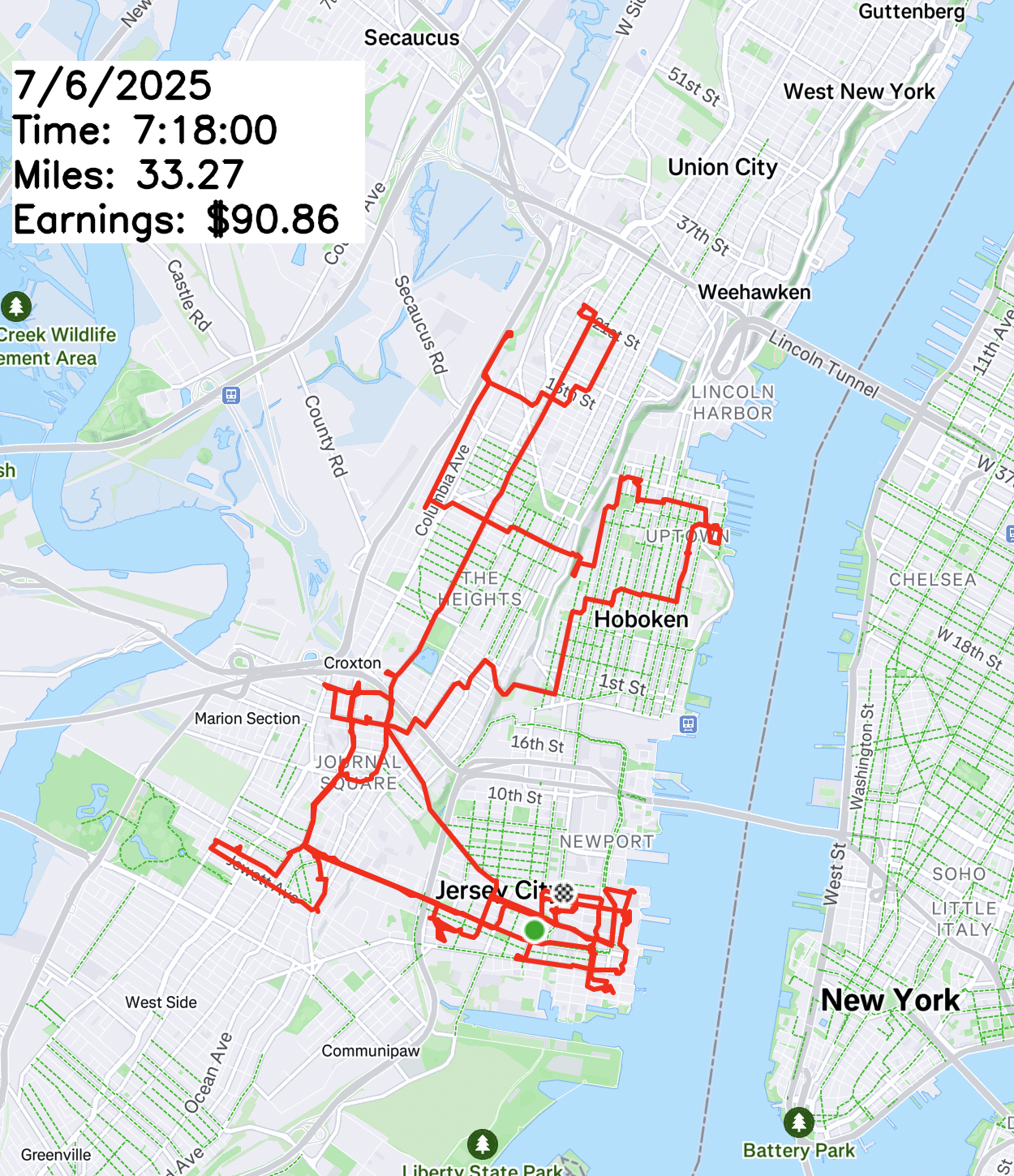
Jersey City, Manayunk, and Philadelphia Center City areas
Research Interests
- High performance computing and optimization, particularly on graphics processing units (GPUs) using CUDA, OpenCL, and directive-based languages
- Applications of high performance computing, specifically as used for financial applications, benchmark suites, and real-time stereo analysis/motion estimation from a pair/sequence of images
Publications and Supplemental Material
- S. Grauer-Gray, W. Killian, R. Searles, J. Cavazos. Accelerating Financial Applications on the GPU. In Sixth Workshop on General Purpose Processing Using GPUs (GPGPU 6) 2013.
- Presentation Slides
- Code (any work using this code should cite above paper)
- Zhan Yu, Christopher Thorpe, Xuan Yu, Scott Grauer-Gray, Feng Li, and Jingyi Yu. Racking Focus and Tracking Focus on Live Video Streams: A Stereo Solution. In The Visual Computer, February 2013.
- S. Grauer-Gray, L. Xu, R. Searles, S. Ayalasomayajula, J. Cavazos. Auto-tuning a High-Level Language Targeted to GPU Codes . In Proceedings of Innovative Parallel Computing (InPar) 2012. (See IEEE Disclaimer below)
- Presentation Slides
- Intial PolyBench/GPU Benchmark Suite used for results in paper and updated version that matches format of Polybench 3.2 and adds OpenACC/OpenMP versions of each benchmark (any work using either code should cite above paper)
- Zhan Yu, Christopher Thorpe, Xuan Yu, Scott Grauer-Gray, Feng Li, and Jingyi Yu. Dynamic Depth-of-Field on Live Video Streams: A Stereo Solution. In Computer Graphics International (CGI) 2011.
- S. Grauer-Gray, J. Cavazos. Optimizing and Auto-tuning Belief Propagation on the GPU. In The 23rd International Workshop on Languages and Compilers for Parallel Computing (LCPC) 2010.
- S. Grauer-Gray, C. Kambhamettu. Hierarchical Belief Propagation To Reduce Search Space Using CUDA for Stereo and Motion Estimation. In IEEE Workshop on Applications of Computer Vision (WACV) 2009. (See IEEE Disclaimer below)
- S. Grauer-Gray, C. Kambhamettu, K. Palaniappan. GPU Implementation of Belief Propagation Using CUDA for Cloud Tracking and Reconstruction. In 5th IAPR Workshop on Pattern Recognition in Remote Sensing (PRRS) 2008. (See IEEE Disclaimer below)
- Code (any work using this code should cite above paper)
- Relative speedup across various processors using updated code:
- NVIDIA H100 (GH100): 3.34x
- AMD Genoa-X (176 Cores across 2 CPUs): 2.31x
- NVIDIA H100 (PCIe): 2.27x
- AMD Genoa-X (88 Cores): 2.12x
- AMD Genoa (96 Cores): 1.98x
- Amazon Graviton4 (96 ARM cores): 1.97x
- Microsoft Cobalt (96 ARM cores): 1.91x
- NVIDIA A100: 1.89x
- Intel Emerald Rapids (48 cores): 1.84x
- RTX 3090 Ti: 1.65x
- Intel Sapphire Rapids (48 cores): 1.53x
- NVIDIA Grace CPU in GH200 (64 ARM Cores): 1.44x
- AMD Milan-X (60 Cores): 1.37x
- Amazon Graviton3 (64 Cores): 1.20x
- NVIDIA V100: 1.15x
- AMD Rome (48 Cores): 1.00x
- Intel Ice Lake (32 Cores): 1.00x
- Amazon Graviton2 (64 Cores): 0.90x
- NVIDIA P100: 0.78x
- Intel Cascade Lake (24 Cores): 0.66x
- Spreadsheet with detailed results
- Follow-up 'paper' (2019): "Optimizing Global Stereo Matching on NVIDIA GPUs and CPUs"
- Describes additional CUDA code optimizations with evaluation on multiple GPUs including Tesla V100.
- Introduces parallel CPU implementation using OpenMP, SIMD instructions, and the same optimizations as the CUDA code, with evaluation on multiple CPUs.
- TLDR #1: Was able to get a speedup of over 2x on many tests with no loss of accuracy by (1) getting rid of many cudaMalloc()/cudaFree() calls, (2) using 16-bit half precision data rather than 32-bit floats, and (3) improving data alignment.
- TLDR #2: Parallel/optimized CPU implementation much faster than initial non-parallel code, but optimized CUDA implementation on Tesla V100 is still 1.9x-4.2x faster than optimized CPU implementation on 24-core Xeon CPU.
- Second follow-up 'paper' (2025): "Optimized Parallel Belief Propagation on NVIDIA GPUs and CPUs"
- Processors benchmarked:
- NVIDIA GPUs: H100, A100, RTX 3090 Ti
- x86 CPUs: AMD Genoa, Intel Emerald Rapids
- ARM CPUs: Amazon Graviton4, Azure Cobalt, NVIDIA Grace
- Abstract: Parallel processing is a common way to speed up many computer vision algorithms including stereo matching. This work looks at optimized parallel implementations of belief propagation for stereo processing on NVIDIA GPU and x86/ARM CPU architectures and shows runtime comparisons across multiple GPU and CPU processors on a variety of input stereo sets. The work goes on to present and show results of retrieving an optimized parallel configuration for each input stereo set, speedups/slowdowns when using 16-bit floats and 64-bit doubles compared to 32-bit floats, and speedups when using templated disparity counts that allow the iteration counts of loops that iterate through possible disparities to be known at compile time.
© 20xx IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.